linux文件系统如何进行文件存取
乍一看,这个题目好像有点小儿科。
写文件嘛
echo hello > /tmp/foo
读文件嘛
cat /tmp/foo
对于普通文件的存取,的确可以使用上面的方法。但是在linux操作系统上,一
切都是文件。除了普通文件,还包括:目录,符号链接,IPC Endpoints(如pipe,unix socket)和设备文件(块设备,字符设备)。
当然,本文的重点不在于介绍相关操作技巧,而是希望可以探寻操作背后的机制。
我们要存取的文件,一般都是保存在普通的磁盘上,通过电磁变换来实现文件的读取和写入。所以我们先从磁盘说起。
磁盘物理结构
磁盘的机械结构如下图:
,一个盘片上的盘面被划分成若干个同心圆(即<code>磁道</code>(track))。<br>将磁盘上<code>机械臂</code>的<code>磁头</code>径向移动到盘面的相关位置(磁道)后,通过盘片在磁头下方的高速旋转,就可以读取并写入所在<code>柱面</code>(cylinder)上的数据。</p>
<p><em>盘面的示意图如下</em>:</p>
{% img /images/os/disk-structure-2.gif disk strucrure")
磁盘是个块设备,它的最小存储单位是扇区(sector),每个扇区存取512字节。
为了提升文件的读取效率,文件系统会以块(block)为单位进行文件读取。块是linux系统上文件存取的最小单位,一个块一般为连续的8个扇区,即4K。
直接对磁盘等硬件进行操作,是很困难的。不过操作系统的主要任务就是隐藏硬件,呈现良好,清晰,优雅,一致的抽象。linux文件系统对文件的处理进行了良好的抽象。
VFS虚拟文件系统
linux文件系统的体系结构图如下:

- 一块硬盘会被划分成多个分区
- 每个分区挂载着相应的文件系统具体实现,如ext2
- 为了减少需要管理的block的数量,在ext2文件系统产生了块组的概念。每个块组包含多个block,并且有独立的superblock和inode。
相关名词说明
Boot Sector
即引导扇区。包括:本分区的操作系统类型,数据区大小,根目录区允许的最大目录项
Super Block
超级块。定义了文件系统的静态结构,包括:分区中每个block的大小,分区中block group的数目,以及每个block group中有inode等。每个block group不一定都有超级块,其他block group中的超级块仅仅是block group 0中超级块的一个拷贝,以备当block group 0中的超级块损坏时可以对其进行恢复。Linux启动时,block group 0中的超级块的内容会被读入到内存中。
GDT
组描述符表。记录了块位图(Block Bitmap)所在块的块号,inode位图(inode Bitmap)所在块的块号,inode表(inode Table)所在块的起始块号,本组空闲块的个数等组内信息。文件系统根据这些信息来查找数据块位图,索引结点位图,索引结点表的位置
Block Bitmap
Ext2文件系统的数据块位图。其中每一位对应了一个数据块,某一位上位0时表示该位所对应的数据块空闲,反之表示该位所对应的数据块已经被分配。Data Block Bitmap占了1个块的空间,因此,一个组中的数据块的个数就已经决定了。如果每个块为b-byte,那么该Group Block就有8b个块,可以存放(8b)*b字节的数据
Inode Bitamp
inode节点位图。其工作方式跟Block Bitmap相同,只不过代表的是Inode的使用情况,每个位代表一个inode,如果是1则表示被使用,为1表示空闲
Inode Table
存储inode number对应文件的元信息,包括:文件类型,权限位,链接数(有多少文件名指向这个inode),文件数据块的位置。
Data Blocks
数据块存放文件的实际内容。需要特别指出的是,在Linux下目录也是一种文件。目录中的文件及子目录都以目录项(directory entry)的形式存放在该目录的数据块中。目录项中主要记录了文件的inode号,文件名以及文件类型等内容
Linux开机启动时,会首先载入MBR(主引导记录),MBR会告诉电脑从该设备的某一个分区来装载boot loader(boot loader储存有操作系统的相关信息,比如操作系统名称,操作系统内核 (kernel)所在位置等),通过boot loader会加载kernel,kernel通过initrd加载硬件驱动,在主分区表中搜索活动分区,加载引导分区,挂载文件系统,进行操作系统的启动。
文件查找示例
以查找文件/home/alex/foobar为例进行说明。
假设根目录(ROOT directory),在磁盘空间上的inode number是2,其对应数据块的结构如下
+—-+—–+—————————————–+
#2 |. 2 |.. 2 | home 5 | usr 9 | tmp 11 | etc 23 | … |
+—-+—–+—————————————–+
通过跟目录下home目录的名字home,可以获取其inode number是5,其对应数据块的结构如下
+—-+—–+—————————————————+
#5 |. 5 |.. 2 | alex 31 | leslie 36 | pat 39 | abcd0001 21 | … |
+—-+—–+—————————————————+
通过home目录下alex目录的名字alex,可以获取其inode number是31,其数据块的结构如下
+—-+—–+—————————————————+
#31 |. 31|.. 5 | foobar 12 | temp 15 | literature 7 | demo 6 | … |
+—-+—–+—————————————————+
继续查看inode number是12(foobar文件)的inode所对应的数据块结构,就可以获取路径为/home/alex/foobar的文件的数据内容。
———–
#12 | file data |
———–
从上面也可以看出
- 目录也是一种文件,其中包含了该目录下子目录的名字和文件名,以及其对应的inode number。
- 文件名和inode number,是多对一的关系。多个文件名可以对应同一个inode number(硬链接)
为了访问路径为/home/alex/foobar的文件的数据,需要有合适的权限在根目录的inode,home目录的inode,alex目录的inode,foobar数据文件的inode。
- 目录的inode权限,决定了是否有权限修改,移动,删除该目录,以及目录下的文件。
- 文件的inode权限,决定了是否有权限读取或者修改该文件的内容。
文件存取流程
在进行文件存取时,实际上就是解析文件路径,加载相应分区上的inode table,获取对应的inode number,对inode number对于的数据块进行存取。
对于访问过的文件路径,会被缓存在dentry目录项中。
为了提升磁盘设备的IO性能,操作系统会使用内存作为磁盘设备的cache,并使用memory map方式在访问时建立与文件系统的缓存映射。文件系统的缓存,是以Page Cache为单位,一个Page Cache包含多个Buffer Cache。
向文件中写入数据时,数据会先缓存在Page Cache中,内存中的这部分数据被标注为Dirty Page,linux系统上的pdflush守护进程会跟进系统设置将将这部分Dirty Page刷到磁盘上,也可以通过fsync系统调用在数据写入后强制刷到磁盘上。将写入的数据刷入磁盘时,是以Buffer Cache为单位,每次回写若干个Buffer Cache。
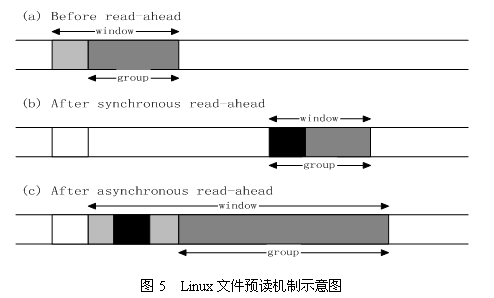
读取文件内容时,系统会一次性连续读取包括所请求页面在内的多个页面(如预读页面个数为n)。如果请求的页面在page cache中命中的话,会从缓存中返回页面内容,增加读取的页面数量,异步读取2n个页面;如果请求的页面没有在page cache中命中,也会增加读取页面数量,同步读取2n个页面。
预读机制示意图
Author: GaoYuan
Link: https://blog.gaoyuan.xyz/2014/03/29/read-wirite-on-linux-file-system/
Use Soulens: Know Destiny, Chart Journey
License: 知识共享署名-非商业性使用 4.0 国际许可协议